Aha, also 25,2 Sekunden für den Durchlauf. Toll! Mal weitersehen.
Test 2 – Ausführung als nativ kompilierte Anwendung
Für diesen Test kompilieren wir den Code mit folgenden Parametern.
Und starten das Programm mit:
Wie geil! Wir haben einen eindeutigen Gewinner!
Dotnet ist ja so schlecht! Wir haben fast 10 Sekunden Unterschied zwischen den Messergebnissen! Microsoft kann eigentlich einpacken!
Oder vielleicht auch nicht!
Nö, der erste Test ist Murks! Weil er nämlich den Code nicht im Release- sondern im Debug-Modus ausführt wurde.
Die in der Release-Konfiguration aktivierten Optimierungen sind darauf ausgelegt, die Ausführungseffizienz der Anwendung zu maximieren. Diese Optimierungen können die Ausführungsgeschwindigkeit erheblich verbessern, indem sie den Code straffen, die Anzahl der CPU-Zyklen reduzieren, die für bestimmte Operationen (im Debug-Modus) benötigt werden, und den allgemeinen Speicherverbrauch der Anwendung optimieren.
Als denn, Test 1 nochmal!
Test 3 – Ausführung als Dotnet-Anwendung im Release-Modus
Wie oben beschrieben, werden wir diesen Test jetzt im Release-Modus ausführen, so wie auch der native Test ausgeführt wurde, mit allen Compiler-Optimierungen.
AHA!
Wir sehen, dass zumindest in Sachen Ausführungsgeschwindigkeit der Roslyn-Compiler einen Super-Job macht. Für den initialen Start einer Anwendung, also vom drücken der Enter-Taste bis zum ersten Ausführen des Codes mag geringfügig mehr Zeit vergehen, da ja der IL-Code erst gebaut werden muss (siehe nächste Grafik und Erklärung).
Danach jedoch ist er in keiner Weise langsamer als der native, direkt für das System kompilierte Programm.
Dann doch noch ein Architekturvergleich
Ich habe mir mal den Spaß gemacht, beide Tools auf jeweils unterschiedlichen Architekturen laufen zu lassen.
Unterschiedliche Architekturen meint hier
Native amd64
Hierfür habe ich picalc für die Intel x64 Architektur mit bflat kompiliert und auf dem o.g. Host System laufen lassen.
Das bedeutet Intel XEON E5-2680 v4 – 2 x 14 Kerne, 128 GB RAM
Auch hier wird picalc mit 99.999.999 Iterationen ausgeführt.
Das Ergebnis sehen wir hier.
Also 15.4 Sekunden für den Test und damit nicht wesentlich schneller als in einer VM. Ist auch irgendwie logisch, da die Art der Berechnung (irre viele, nicht parallelisierte Iterationen), machen auf Host oder VM keinen zeitlichen Unterschied.
.Net Core M1 – arm64
Hierfür lasse ich picalc als Dotnet-Anwendung im Release-Modus laufen.
Als Hardware dient ein Macbook Pro mit dem kleinsten M1 Chip und 16 Gigabyte RAM. Soll heißen, fürchterlich unterlegen gegenüber dem XEON-Kraftprotz!
Was für ein Unterschied!
Wie auch immer das funktioniert, rechnet der M1, obwohl kleiner Consumer CPU, 50% schneller als eine (theoretisch) viel potentere Intel-CPU.
Man könnte jetzt picalc für Multithreading umbauen um zu schauen ob mehrere XEON-Kerne hier effizienter arbeiten als ein einziger Single-Kern.
Hm… na gut, lässt einem ja doch keine Ruhe!
Architektur- und Performance-Vergleich mit einer Multithreaded-Anwendung
Hierfür müssen wir die Methode für die Berechnung von Pi ein wenig umbauen. Wir verwenden dafür die Methode Parallel.For aus dem .Net-Framework. Allerdings müssen wir hier aufpassen!
Einem oder mehreren Taks ist die Reihenfolge Wurscht in der die fertigen Tasks die Ergebnisse verarbeiten.
In dieser Version wird lockObj als Synchronisationsobjekt verwendet, um den Zugriff auf sum zu synchronisieren. Dieses Muster vermeidet den direkten Lock auf sum, da lockObj ein Objekt vom Typ object ist, welches ein Referenztyp ist und daher für das lock-Statement verwendet werden kann.
Die Verwendung von lokalen Teilsummen in Kombination mit einem separaten Lock-Objekt minimiert den Synchronisationsaufwand und ermöglicht es den Threads, den Großteil ihrer Arbeit parallel und unabhängig durchzuführen, wodurch die Wahrscheinlichkeit von Engpässen reduziert wird. Denken Sie daran, die Leistung mit dieser Methode zu testen, um sicherzustellen, dass sie Ihren Anforderungen entspricht.
Ergebnisse der Multi-Threaded-Berechnungen
Nunja, jetzt zeigt sich, dass 2 x 14 Kerne des Intel XEON Prozessors (leider nur) unwesentlich mehr Performance leisten als die (IMHO) 10 Kerne vom Mac M1.
Ergebnis der Multi-Threading-Berechnungen vom Mac M1 mit 10 Kernen.
Ergebnis der Multi-Threading-Berechnungen vom Intel XEON E5-2680 mit 28 Kernen.
Die 28 Kerne der Intel-CPU rechnen 100ms schneller als die 10 Kerne des Mac M1.
Besonders effizient ist das zwar nicht, betrachtet man die reine Core-Anzahl. Aber für irgendwas muss das Intel Ding ja gut sein.
Der, wesentlich, elegantere Weg
Mit gleichen Messergebnis, jedoch mit viel „schöneren“ Source können wir die Berechnung von Pi auch so darstellen:
Hier verwenden wir PLINQ (Parallel Language Integrated Query) und den komplett funktionalen Ansatz für die Berechnung von Pi.
Warum 2 Funktionen?
GenerateLongSequence ist eine Hilfsfunktion, da bspw. Enumeable.Range als Endewert max. Int entgegen nehmen kann. Da wir aber mit sehr großen Iterationen arbeiten wollen, bauen wir uns einfach unsere eigene Sequenz zusammen.
Der Rest ist clean, funktional und nutzt die Möglichkeiten der Programmiersprache optimal aus.
Aber trotzdem…
Die verwendete Funktion ist hierbei noch sehr gut lesbar. Jedoch durch die Bildung von jeweils 3 Variable (a, b und c) und der immer wiederkehrenden Zuweisung und Berechnung, nicht sehr effektiv, hinsichtlich Speichernutzung und CPU-Resourcen.
TL;DR;
Wenn man den Code wie folgt optimiert und mit 99.999 Millionen Iterationen ausführt spart man gegenüber der vorher gezeigten Methodik und der parallelen Ausführung ca. 150ms (statt 1.2 Sekunden nur noch 970ms) auf einem MacBook mit M1 Pro (kleinste Ausführung).
Man könnte jetzt noch die Geschwindigkeit erheblich verbessern, indem man die Genauigkeit bei der Berechnung von decimal (das erkennt man an den lustigen Cast 4m bzw. 2m in der Funktion InternalCalcFnc bspw. ändert in Double-Precision. Also statt 4m –> 4d usw.
Natürlich müssen dann noch die ganzen Rück- und Übergabe-Typen von decimal auf double geändert werden.
Damit büßt man jedoch die Hälfte der Genauigkeit bei der Berechnung ein (28 signifikante Stell bei decimal und 15 signifikante Stellen bei double).
Tatsächlich spart man durch die Änderung des Datentyps von decimal in double auch 50% der Rechenzeit.
Berechnung mit decimal:
Pi with 99999999 iterations in multi threaded mode is 3,1415926535897932384626435306 in 1126,9059ms
Berechnung mit double:
Pi with 99999999 iterations in multi threaded mode is 3,1415926535897936 in 556,5669ms
Fazit
Für die meisten Anwendungsfälle ist die Ausführung als native Anwendung schlicht nicht notwendig. Wenn ich die Anforderung habe im HP-Bereich Anwendungen zu schreiben, würde hier nicht nativ kompilierter C#-Code zum tragen kommen, sondern direkt plattform-optimierter C Code.
Anyway, der Anspruch dieses Beitrags ist nicht der HP-Sektor, sondern was möglich ist.
Aber was ist denn nun ein Nachteil vom Dotnet-Framework und Roslyn?
Roslyn selbst ist weder ein Just-In-Time (JIT) noch ein Ahead-Of-Time (AOT) Compiler im klassischen Sinn. Stattdessen ist es ein Compiler-Framework, das Quellcode in Microsoft Intermediate Language (MSIL, auch bekannt als CIL) übersetzt, ähnlich wie die traditionellen C#- und VB.NET-Compiler. Die resultierende MSIL wird dann zur Laufzeit von der .NET-Runtime entweder JIT-kompiliert (Just-In-Time) oder kann durch Technologien wie .NET Native in einen AOT-Prozess (Ahead-Of-Time) involviert werden.
Nachfolgende Grafik demonstriert, was passiert wenn eine .NET (mit Roslyn) kompilierte Anwendung ausgeführt und was geschieht, wenn die Anwendung nativ ausgeführt wird.
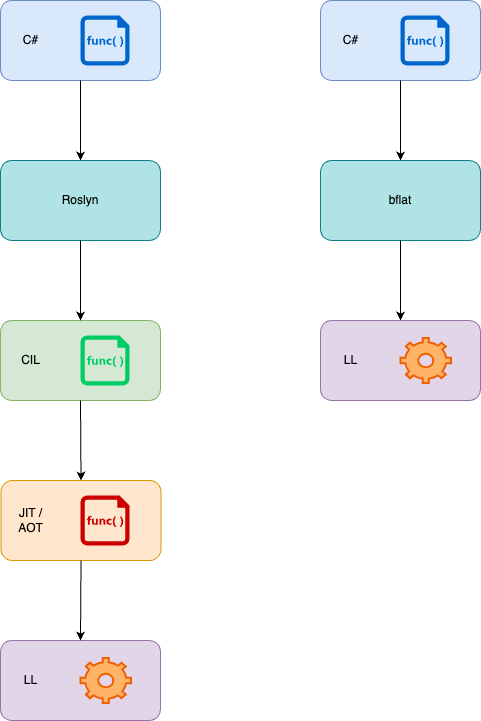
Auf der linken Seite wird der C#-Code durch Roslyn in CIL (Common Intermediate Language) kompiliert. Dieser Code ist jedoch noch nicht auf dem jeweiligen System lauffähig, sondern benötigt beim Start einen JIT (Just in time) Compiler. Dieses ist die häufigste Anwendungsform. Alternativ kann auch ein AOT (Ahead of time) Compiler eingesetzt werden, welcher jedoch nur in ganz bestimmten Anwendungsfällen benutzt wird. Der JIT- / AOT-Compiler erzeugt letztendlich, den für die Plattform ausführbaren maschinenlesbaren (Low Level) Code.
Dagegen wird auf der rechten Seite, der C#-Code mittels bflat exakt für die Plattform kompiliert und kann bei Bedarf direkt (oder eben nativ) auf dieser Platform, ohne weitere Tools / Compiler ausgeführt werden.
Der Nachteil von AOT bzw. .NET Native ist, dass er sehr eingeschränkt native Anwendungen kompilieren kann (derzeit nur UWP). Aber wer schreibt schon noch Anwendungen für UWP? Ist das nicht tot?
Dann gibts vielleicht noch CoreRT.
Das ist aber seit 2020 bei github readonly und auch tot.
Also brauche ich eigentlich immer eine Runtime um meine Anwendung auf dem jeweiligen Zielsystem laufen zu lassen.
Wenn ich also native Anwendungen in meiner Lieblingssprache entwickeln will, die einfach nur durch unterschiedliche Compiler-Konfigurationen ratz fatz für unterschiedliche Plattformen Programme erzeugt werden und dafür keine Framework-Runtime benutzen möchte, ist bflat eine coole Alternative. Selbstverständlich kann ich auch Sprechen wie C, C++, Go oder Rust verwenden um hiermit, plattformabhängig, native Anwendungen für die jeweilige Architektur schreiben, aber jetzt reiht sich in diese Sprachen eben auch C# ein.
Mal abgesehen davon, dass ich komplett abgefahrene Dinge tun kann, in dem ich die zero-Stdlib verwende und dann mal eben in c# ein UEFI-Bootloader schreiben kann!
Urst fetzig sage ich da mal!
Und jetzt, viel Spaß beim Lesen.